Gamma Process Prior for Semiparametric Survival Analysis
Heads up: equations may not render on blog aggregation sites. See original post here for good formatting. If you like this post, you can follow me on twitter.
Motviation
Suppose we observe survival/event times from some distribution \[T_{i\in1:n} \stackrel{iid}{\sim} f(t)\] where \(f\) is the density and \(F(t)=1-S(t)\) is the corresponding CDF expressed in terms of the survival function \(S(t)\). We can represent the hazard function of this distribution in terms of the density, \[\lambda(t) = \frac{f(t)}{S(t)}\] The hazard, CDF, and survival functions are all related. Thus, if we have a model for the hazard, we also have a model for the survival function and the survival time distribution. The well-known Cox proportional hazard approach models the hazard as a function of covariates \(x_i \in \mathbb{R}^p\) that multiply some baseline hazard \(\lambda_0(t)\), \[ \lambda(t_i) = \lambda_0(t_i)\exp(x_i'\theta)\] Frequentist estimation of \(\theta\) follows from maximizing the profile likelihood - which avoids the need to specify the baseline hazard \(\lambda_0(t)\). The model is semi-parametric because, while we don’t model the baseline hazard, we require that the multiplicative relationship between covariates and the hazard is correct.
This already works fine, so why go Bayesian? Here are just a few (hopefully) compelling reasons:
- We may want to nonparametrically estimate the baseline hazard itself.
- Posterior inference is exact, so we don’t need to rely on asymptotic uncertainty estimates (though we may want to evaluate the frequentist properties of resulting point and interval estimates).
- Easy credible interval estimation for any function of the parameters. If we have posterior samples for the hazard, we also get automatic inference for the survival function as well.
Full Bayesian inference requires a proper probability model for both \(\theta\) and \(\lambda_0\). This post walks through a Bayesian approach that places a nonparametric prior on \(\lambda_0\) - specifically the Gamma Process.
The Gamma Process Prior
Independent Hazards
Most of this comes from Kalbfleisch (1978), with an excellent technical outline by Ibrahim (2001).
Recall that the cumulative baseline hazard \(H_0(t) = \int_0^t \lambda_0(t) dt\) where the integral is the Riemann-Stieltjes integral. The central idea is to develop a prior for the cumulative hazard \(H_0(t)\), which will then admit a prior for the hazard, \(\lambda_0(t)\).
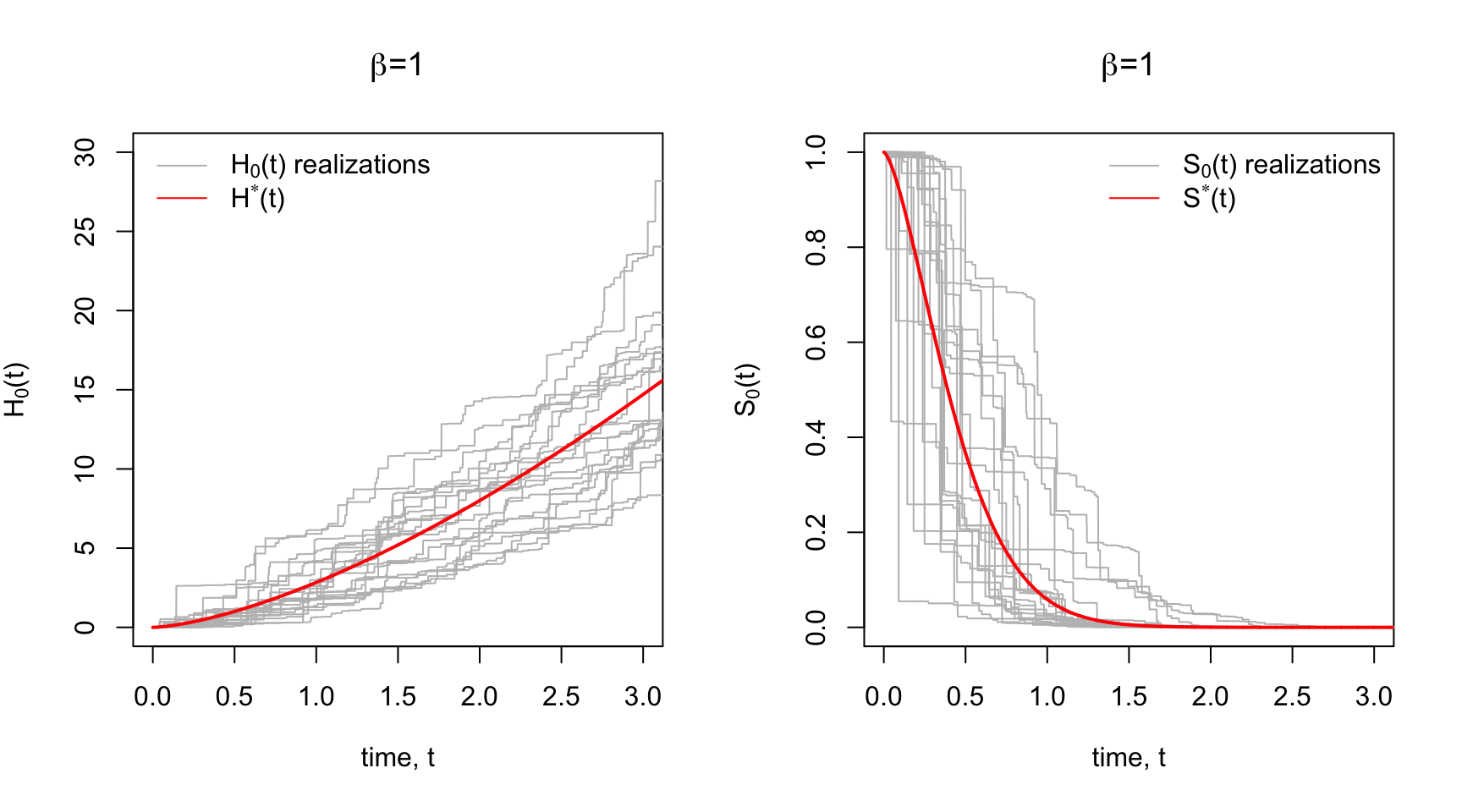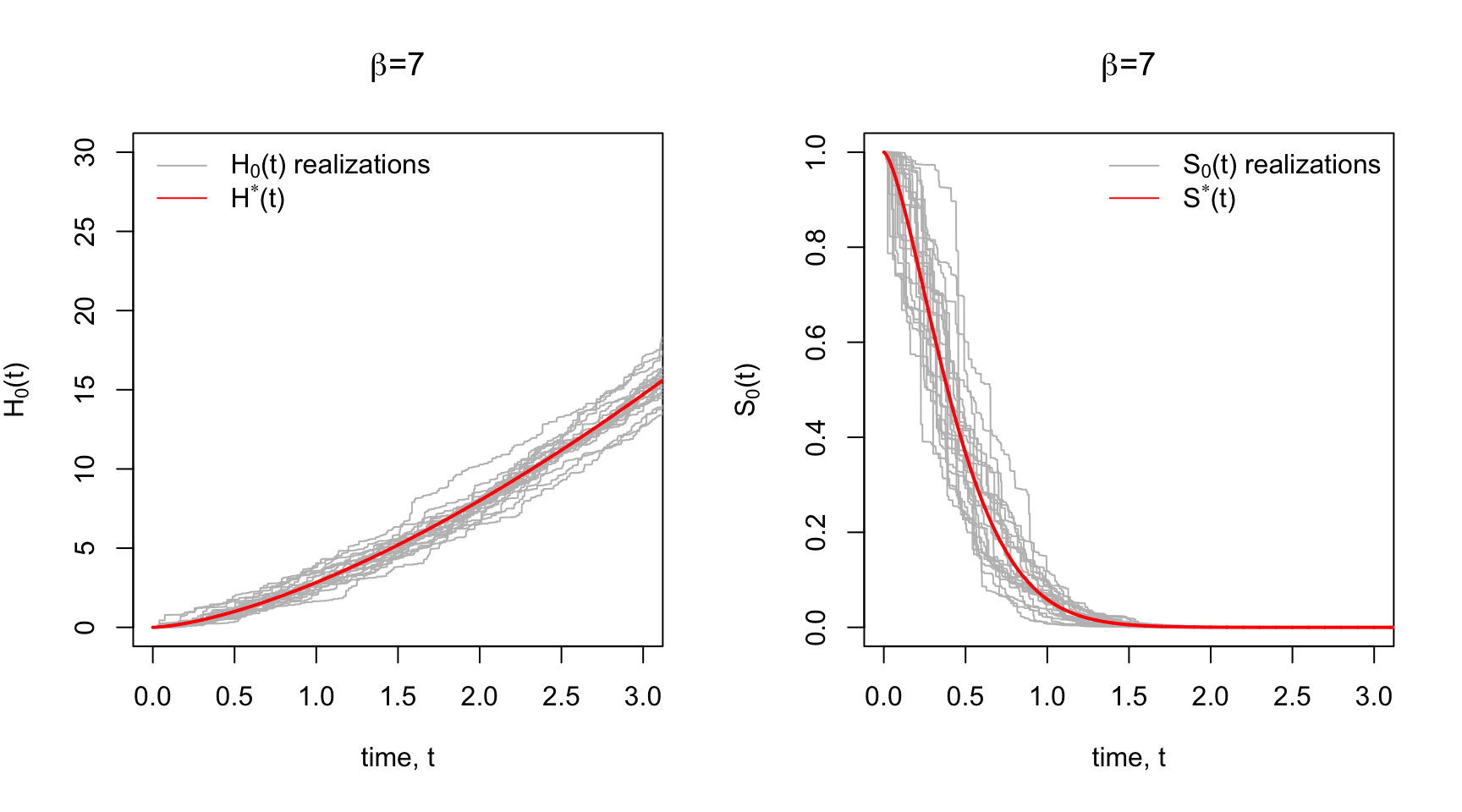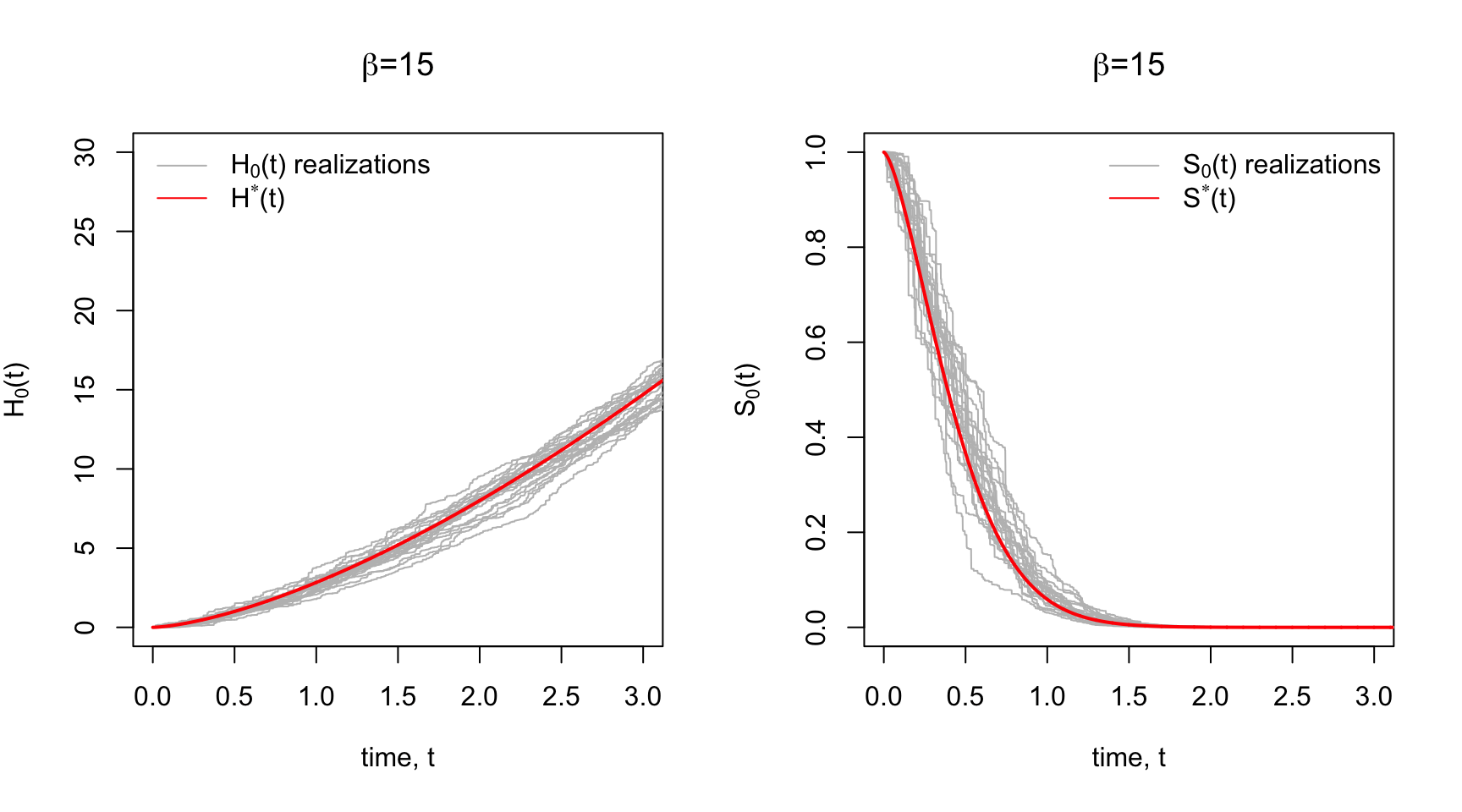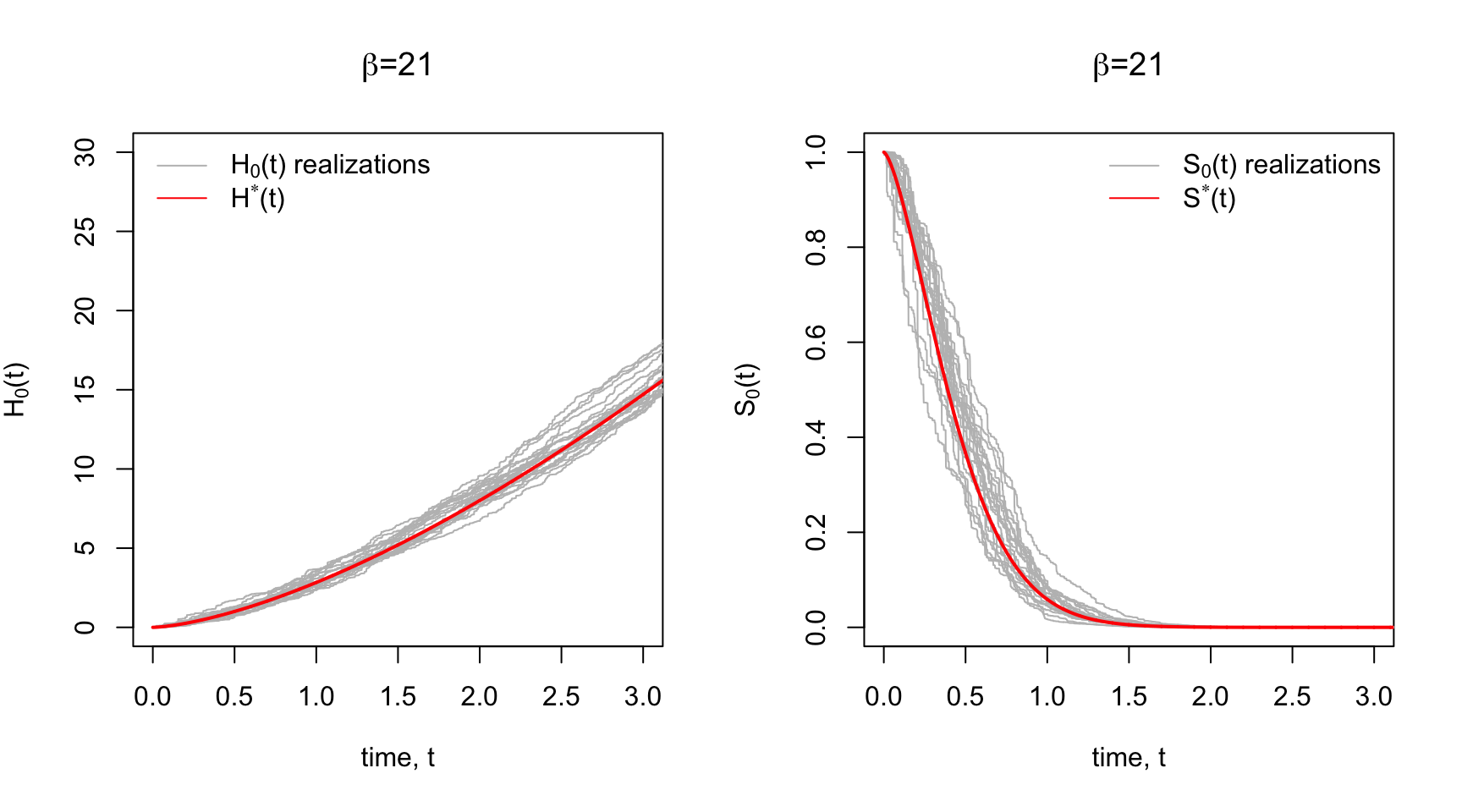
The Gamma Process is such a prior. Each realization of a Gamma Process is a cumulative hazard function that is centered around some prior cumulative hazard function, \(H^*\), with a sort of dispersion/concentration parameter, \(\beta\) that controls how tightly the realizations are distributed around the prior \(H^*\).
Okay, now the math. Let \(\mathcal{G}(\alpha, \beta)\) denote the Gamma distribution with shape parameter \(\alpha\) and rate parameter \(\beta\). Let \(H^*(t)\) for \(t\geq 0\) be our prior cumulative hazard function. For example we could choose \(H^*\) to be the exponential cumulative hazard, \(H^*(t)= \eta\cdot t\), where \(\eta\) is a fixed hyperparameter. By definition \(H^*(0)=0\). The Gamma Process is defined as having the following properties:
- \(H_0(0) = 0\)
- \(\lambda_0(t) = H_0(t) - H_0(s) \sim \mathcal G \Big(\ \beta\big(H^*(t) - H^*(s)\big)\ , \ \beta \ \Big)\), for \(t>s\)
The increments in the cumulative hazard is the hazard function. The gamma process has the property that these increments are independent and Gamma-distributed. For a set of time increments \(t\geq0\), we can use the properties above to generate one realization of hazards \(\{\lambda_0(t) \}_{t\geq0}\). Equivaltently, one realization of the cumulative hazard function is \(\{H_0(t)\}_{t\geq0}\), where \(H_0(t) = \sum_{k=0}^t \lambda_0(k)\). We denote the Gamma Process just described as \[H_0(t) \sim \mathcal{GP}\Big(\ \beta H^*(t), \ \beta \Big), \ \ t\geq0\]
Below in Panel A are some prior realizations of \(H_0(t)\) with a Weibull \(H^*\) prior for various concentration parameters, \(\beta\). Notice for low \(\beta\) the realizations are widely dispersed around the mean cumulative hazard. Higher \(\beta\) yields to tighter dispersion around \(H^*\).
Since there’s a correspondence between the \(H_0(t)\), \(\lambda_0(t)\), and \(S_0(t)\), we could also plot prior realizations of the baseline survival function \(S_0(t) = \exp\big\{- H_0(t) \big\}\) using the realization \(\{H_0(t)\}_{t\geq0}\). This is shown in Panel B with the Weibull survival function \(S^*\) corresponding to \(H^*\).
Correlated Hazards
In the previous section, the hazards \(\lambda_0(t)\) between increments were a priori independent - a naive prior belief perhaps. Instead, we might expect that the hazard at the current time point is centered around the hazard in the previous time point. We’d also expect that a higher hazard at the previous time point likely means a higher hazard at the current time point (positive correlation across time).
Nieto‐Barajas et al (2002) came up with a correlated Gamma Process that expresses exactly this prior belief. The basic idea is to introduce a latent stochastic process \(\{u_t\}_{t\geq0}\) that links \(\lambda_0(t)\) with \(\lambda_0(t-1)\). Here is the correlated Gamma Process,
Draw a hazard rate for the first time interval, \(I_1=[0, t_1)\), \(\lambda_1 \sim \mathcal G(\beta H^*(t_1), \beta)\),
Draw a latent variable \(u_1 | \lambda_1 \sim Pois(c \cdot \lambda_1)\)
Draw a hazard rate for second time interval \(I_2 = [t_1, t_2)\), \(\lambda_2 \sim \mathcal G(\beta( H^*(t_2) - H^*(t_1) ) + u_1, \beta + c )\)
In general for \(k\geq1\), define \(\alpha_k = \beta( H^*(t_k) - H^*(t_{k-1}) )\)
- \(u_k | \lambda_k \sim Pois(c\cdot \lambda_k)\)
- \(\lambda_{k+1} | u_k \sim \mathcal G( \alpha_k + u_k, \beta + c )\)
Notice that if \(c=0\), then \(u=0\) with probability \(1\) and the process reduces to the independent Gamma Process in the previous section. Now consider \(c=1\). Then, the hazard rate in the next interval has mean \(E[\lambda_{k+1} | u_k] = \frac{ \alpha_k + u_k }{\beta+c}\). Now \(u_k \sim Pois(\lambda_k)\) is centered around the current \(\lambda_k\) - allowinng \(\lambda_k\) to influence \(\lambda_{k+1}\) through the latent variable \(u_k\). The higher the current hazard, \(\lambda_k\), the higher \(u_k\), and the higher the mean of the next hazard, \(\lambda_{k+1}\).
Below are some realizations of a correlated and independent Gamma processes centered around the \(Weibull(2,1.5)\) hazard shown in red. One realization is higlighted in blue to make it easier to see the differences between correlated and independent realizations
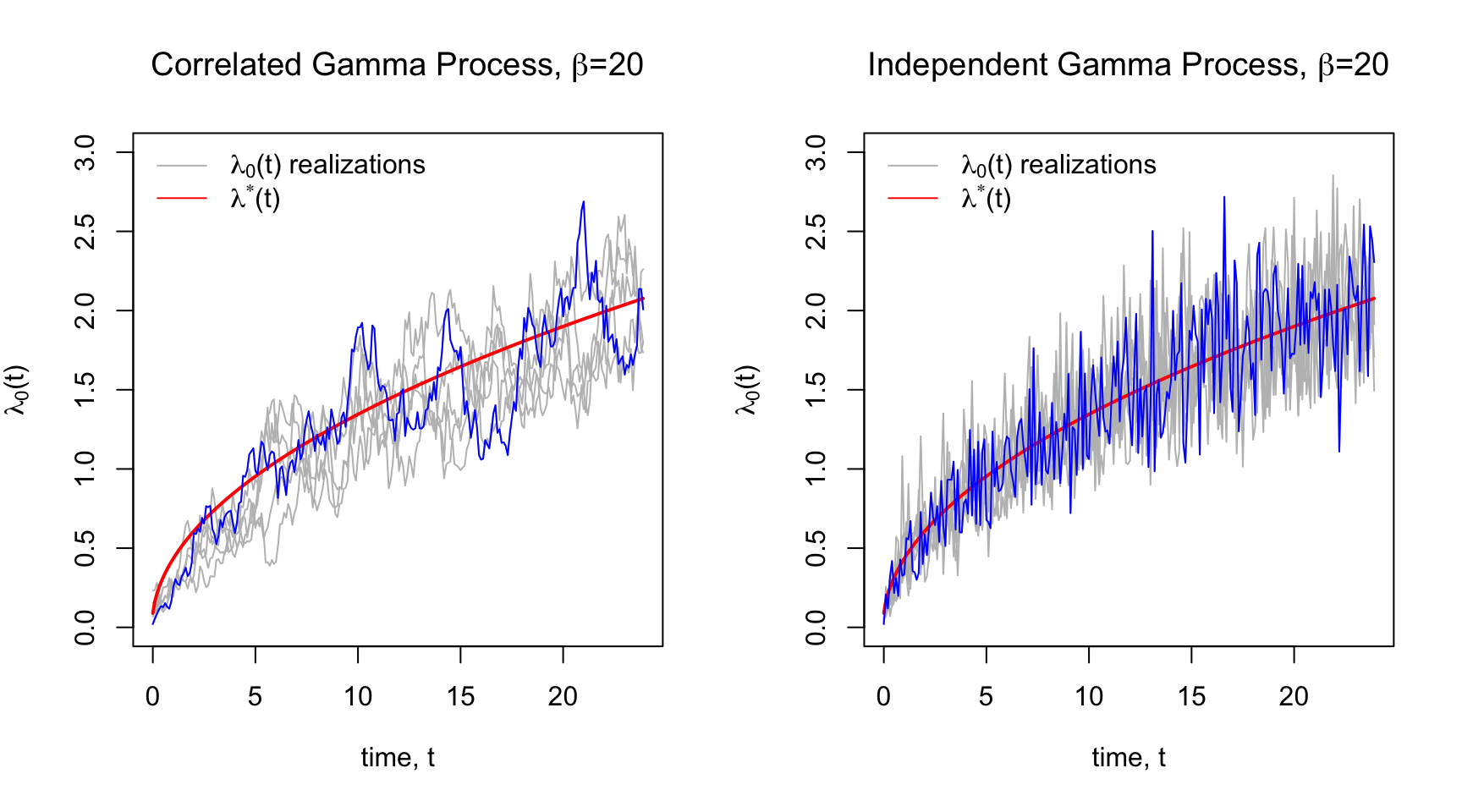
Notice the correlated gamma process looks very snake-y. This is because of the autoregressive structure on \(\{\lambda_0(t)\}_{t\geq0}\) induced by the latent process\(\{ u_t\}_{t\geq0}\).